Problématique
Retour à l'accueilPrise de décision séquentielle et systèmes multi-agents : que sont-ils et pourquoi est-ce important ?
Un grand nombre de tâches décisionnelles, comme le routage de véhicules dans un réseau, le déploiement de publicités ciblées ou même la recherche de nouveaux médicaments, peuvent se ramener à un problème d'optimisation. Sous certaines contraintes, on cherche à prendre des actions qui maximisent ou minimisent un objectif donné.
Au-delà de ce problème statique, les domaines de l'apprentissage en ligne et de la prise de décision séquentielle étudient le cas plus interactif où un acteur doit produire un comportement sous la forme d'une séquence d'actions à optimiser au fil du temps.


Par exemple, les systèmes de recommandation résolvent le problème en ligne consistant à recommander des contenus alignés avec les intérêts d'un utilisateur, en apprenant au fil du temps de son comportement observé. Un robot chargé d'atteindre une cible en un nombre d'étapes donné représenterait, lui, un problème de prise de décision séquentielle, où la trajectoire complète est évaluée au regard de l'objectif à atteindre.
Cela constitue déjà tout un champ de recherche, formalisé à travers la littérature des bandits manchots et de l'apprentissage par renforcement comme principaux objets d'étude.
Plus précisément, lorsque l'objectif n'est pas connu sous forme analytique, ce qui est souvent le cas en pratique, des méthodes ont été développées pour apprendre à partir de formes de signal plus faibles, comme des évaluations (bruitées) de l'objectif, des données de préférence, des interruptions ou même des démonstrations d'un joueur expert (presque) optimal.
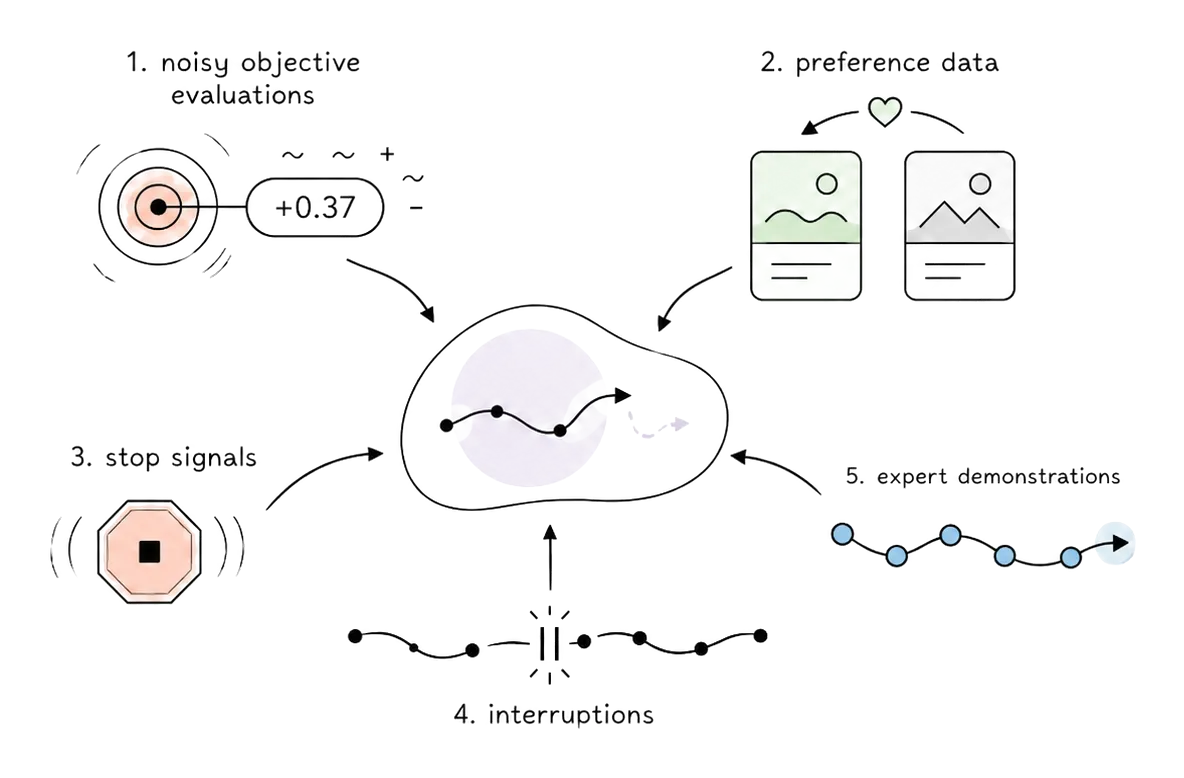
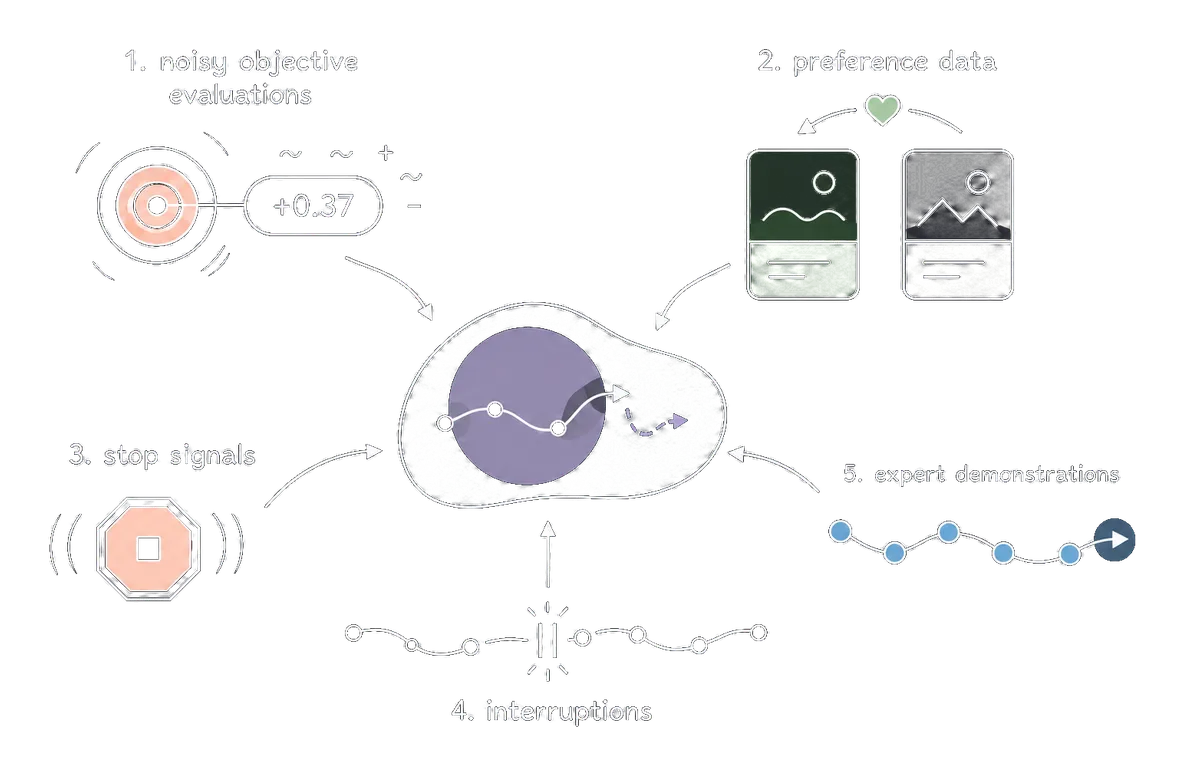
La manière de bien faire cela, de façon prouvée optimale, reste une question ouverte, mais elle a déjà connu d'immenses succès dans des applications telles que la modélisation du langage (affiner le langage à partir des préférences des utilisateurs), la robotique (apprendre des mouvements de danse à partir de vidéos humaines) ou encore le contrôle du plasma de fusion nucléaire.
Dans de nombreux scénarios, toutefois, les agents n'agissent pas de manière isolée mais doivent interagir avec d'autres. Dans ces systèmes multi-agents, la prise de décision stratégique donne naissance à des comportements coopératifs, compétitifs et mixtes.
Comprendre comment agir de façon optimale dans ces situations, sous l'angle de la théorie des jeux et de l'optimisation, est une question largement ouverte, riche de défis distincts. Il existe encore toute une variété de tâches simples que nous ne savons ni formaliser ni résoudre, ce qui motive l'étude des fondamentaux pour permettre les progrès futurs.
À mesure que les robots sont progressivement déployés dans la société, les interactions homme-robot et inter-robots gagnent à la fois un potentiel considérable et une exposition croissante aux risques d'échec. Plus généralement, mes recherches portent sur la manière de rendre ces systèmes de décision autonomes à la fois optimaux et résilients face à des perturbations stratégiques et adversariales.
Avec mes collègues, j'ai eu la chance de contribuer à l'optimisation en ligne et à la théorie des jeux sous différents angles, en considérant à la fois des méthodes efficaces pour apprendre des comportements optimaux dans les systèmes multi-agents et la compréhension de l'exploitabilité stratégique des comportements multi-agents appris.
Dans Preference-Based Distributed Welfare Maximization, nous proposons un cadre algorithmique en ligne pour l'optimisation distribuée d'objectifs inconnus à partir de retours de préférence actifs. Sur la tâche complémentaire de l'apprentissage à partir de démonstrations, nous montrons dans Matching Multiple Experts à quel point les techniques d'apprentissage par imitation peuvent être fragiles dans les systèmes multi-agents, et faisons progresser la compréhension des hypothèses structurelles qui permettent une faible exploitabilité dans les environnements non interactifs.
De nombreuses questions restent encore à explorer, ce n'est que le début du chemin. N'hésitez pas à me contacter si vous êtes curieux de nos travaux ou souhaitez collaborer.